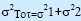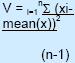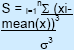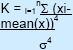16.2 Risk valuation
| Guidance notes - Risk valuation | |||||
| The risk analysis model is of no value unless its result can be communicated. This is necessary not only in presenting the final results, but also in presenting the interim results used to more accurately quantify the significant risks. This section is divided into graphical presentation and statistical measures of risk. | |||||
| Graphical presentation | |||||
| Histogram plots/frequency distributions are the most commonly used plots in risk analysis. The only consideration in histogram plots is the number of bars. Too many bars and the level of random noise dominates, making the plot too detailed and difficult to read. However, too few bars and the detail is missed out. | |||||
| The histogram is very useful for illustrating the degree of uncertainty associated with a variable. However, it is not good for determining quantitative information. The cumulative frequency plot is useful for this - for example, for plotting the probability of achieving a certain NPC outcome, or the probability of a value lying between two values. | |||||
| A histogram plot/frequency distribution will show the shape of a distribution and helps to show clearly where the majority of risks lie. Detailed analysis and comparison of the respective distributions generated for the PSC and the bids should be carried out as part of the documentation of the PSC and the bid evaluation. It is possible that such analysis could result in a bid that lies above the PSC mean case still being considered to show value for money in comparison with the PSC simply because the PPP delivery mechanism provides greater cost certainty and decreases government's exposure to downside risk volatility. | |||||
| Consideration of the histogram plots/frequency distributions may extend to an analysis of measures such as the skewness, kurtosis and variance from the mean. These statistical measures, along with others, are defined and described in Table 16-1. | |||||
| Statistical measures | |||||
| There are many statistics that can be calculated based on a distribution - for example, the standard deviation of a normal distribution. Most of these statistics are unlikely to have any direct relevance to an output report. Table 16-1 lists the most common statistical measures, and explains when they might be useful. | |||||
| Table 16-1: Statistical measures - definitions | |||||
| Statistic | Definition | Use | Dangers | ||
| Mean (expected value) | The average of all the generated outputs | Very useful, for example, as a measure of the average NPV of a transaction. It also has the useful property that if two (or more) variables are independent, then: mean(a+b)=mean(a)+mean(b), and mean(a*b)=mean(a)*mean(b). | Confusing the mean with the most probable (mode) | ||
| Standard deviation (σ) | The square root of the variance | Another very useful statistic, it gives a measure to the dispersion around the mean of a distribution. It is frequently used in conjunction with normal distributions to give the level of certainty that a value lies within a certain amount from the mean: +/- σ of the mean = 68% +/- 2σ of the mean = 95% +/- 3σ of the mean = 99.7% So, for example, a normally distributed variable with a mean of 1.0 and σ=0.05 can be said to have a 95% certainty of lying between 1.1 and 0.9. | (a) Assuming that the
(b) The relationship given in (a) is only valid if the distribution is symmetrical. It becomes more of an approximation the more skewed the distributions are. | ||
| Variance (V) | The variance is calculated by determining the mean of a set of values, and then summing the square of the difference between the value and the mean:
| This is also a measure of the dispersion around the mean. However, it is in the units of a quantity squared. Thus the variance of a distribution in NPV (in $s) will be given in $2. It is useful for estimating the widths of a sum or multiple of several independent variables: V(a+b)=V(a)+V(b), and V(a*b)=V(a)*V(b). | As with standard deviation, the relationships shown to the left are only valid if the distribution is symmetrical. It should be noted that the variance (and thus the standard deviation) is much more sensitive to the values at the tails of the distribution than those close to the mean. | ||
| Median | The median is the value at which there is an equal percentage chance of a variable being above it as below it. In other words, it is the 50th percentile. | Rarely used as it gives no indication as to the range of the values above it or below it. If the mean is not equal to the median, then the distribution is skewed. | Confusing the median with the mean or mode. | ||
| Percentiles | The nth percentile of a variable is that value for which there is an n% chance of the variable lying at or below that value. | A useful concept, used in measuring the range of a variable. For example, the range of a distribution might be defined as the difference between the 5th and 95th percentile. What this means is that the range here is the resulting width of a distribution if the top 5% and bottom 5% of all values are ignored. It can also be used to answer questions like 'What are the chances that the NPC is below $100 million?'. The answer would be the percentile for which the value was $100 million. | Not widely understood, so use everyday terms when quoting it. | ||
| Mode | The most likely value. For a discrete distribution this is the value with the greatest observed frequency, and for a continuous distribution the point of maximum probability. | Sometimes used to describe a Poisson-like distribution: the mode is the most probable event to occur in the given time period (and is approximately given by the reciprocal of the rate). Also used in describing triangular distributions (the minimum, the mode and the maximum). In general it has little value in uncertainty and risk analysis. | It is difficult to determine precisely, particularly if a distribution is unusually shaped. | ||
| Skewness (S) |
| This is a measure of the 'lopsidedness' of a distribution. It is positive if a distribution has a longer right tail (and negative if a more prominent left tail). Zero skewness means the distribution is symmetric. It is used to determine how 'normal' a distribution is. The closer a distribution is to having a skewness of zero, the more normal it is. Examples of skewness: the skewness of normal distribution is 0, triangular distributions vary between 0 and 0.56, and an exponential distribution has a skewness of 2. | The skewness is even more sensitive to the points in the tail of the distribution than the variance. It, therefore, requires many iterations to be run before it reaches a stable value. | ||
| Kurtosis (K) |
| The kurtosis is a measure of the 'peakedness' of a distribution. Examples of kurtosis: uniform distribution has a kurtosis of 1.8, triangular (2.4), normal (3), and exponential has a kurtosis of 9. If a distribution is approximately bell shaped, and has a skewness of around 0 together with a kurtosis of close to 3, then it can be considered normal. | Stable values of the kurtosis often require even more iterations to be run than skewness. For example a randomly sampled normal distribution required approximately 1500 iterations to be within 2% of 3. | ||
| Coefficient of variability (normalised standard deviation) σn | This is defined as the standard deviation divided by the mean: σn = σ / mean | This is a dimensionless quantity that allows you to compare, for example, the large standard deviation of a large variable with the small standard deviation of a small variable. An example would be investigating the comparative level of fluctuation with time between different currencies. | This is not a meaningful statistic to compare if the mean and standard deviation are unlikely to bear any relation to each other. An example would be the NPV of a project. Here the spread need not be related to the mean value, which could be close to zero. An extreme would be the coefficient of variability of a normal distribution that is centred on zero. | ||
| In general, it is more helpful to keep the number of statistics quoted in a report to a minimum (e.g. the mean and the spread between two percentiles), and not quote them to a large number of significant figures. | |||||